
Distributed Proving Architecture
The OpenVM circuit architecture and continuations framework are designed for compatibility with distributed proving coupled with hardware acceleration. Below we describe the components in proving an unbounded zkVM program in a distributed environment supporting GPU hardware acceleration.
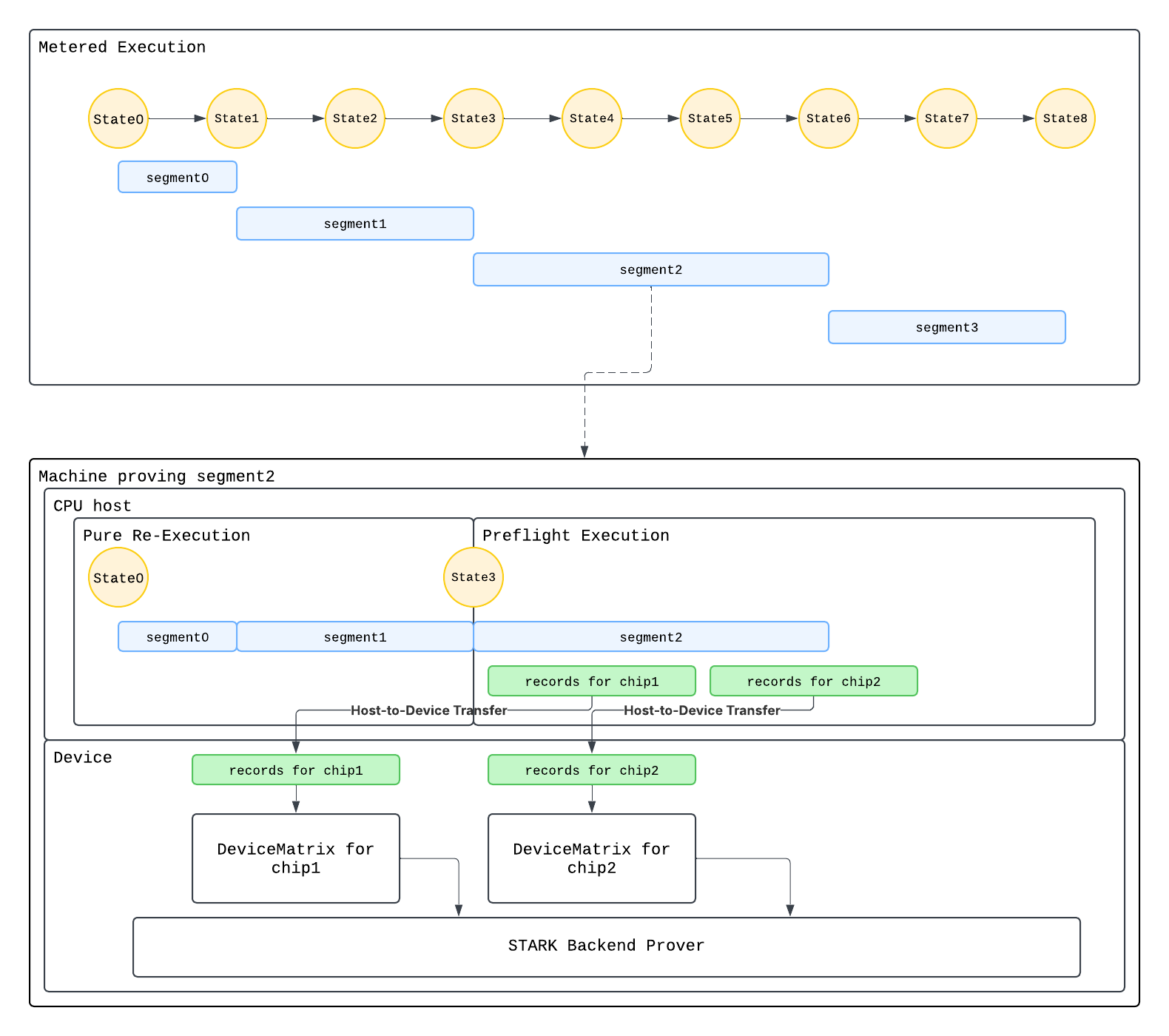
Overview
We give an overview of the distributed proving architecture and then provide further details of each component.
Given a zkVM program with unbounded runtime size, we first perform metered execution to segment the execution into segments on a dedicated CPU machine. Minimal boundary metadata about each segment is sent to a dedicated machine to generate the App proof of that segment. The app proofs are proven in parallel on distributed prover machines. We will refer to each prover machine as consisting of a host and device, where the host consists of the CPU and RAM, and the device may be the multi-core CPU or the GPU depending on the proving backend.
For each segment, we re-execute via pure execution on the host CPU to recover the starting VM state at the beginning of the segment. Then the host performs preflight execution up to the segment end, storing records of the execution into in-memory buffers. During trace generation, these buffers are copied to device memory and transformed on device into trace matrices that match the specifications of the zkVM circuit frontend. Execution is serial, while trace generation is massively parallelized. The STARK backend then generates a cryptographic proof from the trace matrices, on device.
The above process generates all segment App proofs in parallel. After the App proofs are generated, they are aggregated into a single proof via the aggregation tree described in the continuation design. Each layer of the aggregation tree is proven in parallel, where each aggregation proof is treated as a single segment proof.
Modular Abstraction Layers
The distributed proving architecture is designed to be extensible and composable via VM extensions. The architecture allows each VM extension to define their own implementations of execution and trace generation, while a unified hardware abstraction layer ensures:
- Optimized parallelization - VM extensions can implement hardware-specific trace generation algorithms to maximize parallel computation efficiency.
- Decoupled proving backend - The STARK backend prover implements the specifications of the proof system with optimized hardware acceleration while remaining independent of the VM extensions in use.
The hardware abstraction layer defines a host-device boundary: the host comprises the CPU and system RAM, while the device denotes specialized compute hardware featuring architecture-specific memory that operates either independently or in a unified memory model with the host.
We now give more details about the components of the distributed proving architecture discussed in the overview.
Execution
Given an executable consisting of OpenVM instructions, we have several runtimes which run the executable.
We will have three modes of execution:
- Pure execution. This is "normal" VM execution, currently implemented via an interpreter, where execution starts from a specified VM state and executes either a specific number of instructions or until program termination. Pure execution only needs to output the end VM state when execution stops.
- Metered execution. This is pure execution that additionally measures weighted functions of instruction counts and guest memory usage in order to determine where to segment the program execution. The segmentation criteria are designed to account for estimated prover device memory usage and security constraints dependent on the proof system's prime field. The output of metered execution is the sequence of segments together with segmentation-related metadata about the segment boundaries.
- Preflight execution. This is a special logging execution that records the minimal execution trace such that subsequent trace generation may be done in parallel without reliance on the VM state.
- The logging is done by writing records to in-memory buffers referred to as record arenas. During trace generation, these buffers are designed to be transferred to device memory for hardware acceleration purposes.
All modes of execution are inherently serial and performed on a CPU.
Trace Generation
Trace generation is the first point in the proving process where computation occurs on device with hardware acceleration. For a given segment, the preflight execution records contain all the data necessary to generate the trace matrices corresponding to all chips in the zkVM circuit. The records are stored in memory buffers called record arenas, where the buffer memory layout is optimized based on the device type. The records are transported from host to device memory. Then the trace matrices are generated from the records by utilizing as much parallelism as possible. In particular, trace generation for the execution records of different instructions is parallelized and does not need to be done in the order they were executed.
The output of trace generation is an ordered list of trace matrices corresponding to the zkVM circuit's chips. The trace matrices are fully on-device and never leave device memory.
Proof Generation via STARK Backend
The STARK backend takes the proving key of the circuit and the trace matrices output from trace generation and generates a proof on device according to the specifications of the proof system. The proving key is generated upon circuit creation independently of any runtime inputs, and can be transferred to device memory ahead of time. The trace matrices are created on device, so the entire proving process can be done on device utilizing hardware acceleration.
Aggregation
The sequence of App proofs, one per segment, is aggregated using distributed proof aggregation following our continuation design. Proof aggregation proceeds using an aggregation tree, where each node in the same layer of the tree can be proven in parallel.
Each aggregation proof is generated directly via trace generation and STARK backend proving for the corresponding aggregation circuit — no VM execution is involved. Trace generation and STARK backend proving proceed on device as described above.